Behind the Hood: DynamoDB - An Always Available K-V Store
Amazon runs a world-wide e-commerce platform that serves tens of millions customers at peak times using tens of thousands of servers located in many data centers around the world. To serve such application, Amazon needed a system solution where ‘ALL’ customers have a good experience, rather than just the majority. To solve for this Amazon architected a solution that allows customers to view and add items to their shopping cart even if disks are failing, network routes are flapping, or data centers are being destroyed by tornados.
To put this to Amazon’s Scale, In 2022, over the course of Prime Day, Amazon systems made over a trillion calls to the DynamoDB API, and DynamoDB maintained high availability while delivering single-digit millisecond responses, peaking at 105.2 million requests per second. Its no less than an engineering wonder as to how Amazon pulls this off. To understand this better lets go deeper into the How and the What of DynamoDB.
What is DynamoDB, and how is it different from other NoSQL Databases?
DynamoDB is a highly available and scalable distributed key-value store developed by Amazon for providing an always-on experience for business-critical applications. Unlike other NoSQL databases, DynamoDB was not built as an afterthought to address the issues of Amazon's e-commerce business, where even a small outage has serious monetary consequences.
The important point to note in this regard is that DynamoDB was built with a different set of goals in mind: it emphasizes availability over consistency. Unlike other NoSQL databases, DynamoDB was built with the goal of eventual consistency in mind and offers facilities to make it easier for applications to deal with conflicting versions of data. This ensures that customer-facing operations, such as adding items to a shopping cart, never fail even in the presence of network splits or machine failures.
Always On Architecture and High Uptime of DynamoDB
The most interesting aspect of DynamoDB is its "always writable" nature. DynamoDB follows a sloppy quorum approach instead of a strict quorum membership model, where reads and writes are done on the first N healthy nodes in the preference list. This means that the write request will be allowed if at least one node in the system is capable of persisting the data, and the system will never fail to accept customer updates due to transient errors.
The trade-off between availability and consistency is handled by the application using three key parameters: N (replication factor), R (read quorum), and W (write quorum). In its Amazon production environment, DynamoDB has achieved a successful response rate of 99.9995% without timing out and has had no data loss incidents since its inception.
Quorum Configuration: The R + W > N Rule
The consistency level of DynamoDB is modeled using three parameters that can be tuned. R is the minimum number of nodes that must succeed in a read operation, W is the minimum number of nodes that must succeed in a write operation, and N is the number of replicas, usually 3.
Various settings are used for different purposes. The most typical configuration in a production environment is N=3, R=2, W=2, where R + W = 4 > N, which balances consistency, availability, and performance and handles the failure of one node.
For highly available write operations, such as the shopping cart service, N=3, R=3, W=1 is employed, where writes never fail because only one node is required, and strong consistency for reads is required, making it critical for "always writeable" services. At the other end of the spectrum, N=3, R=1, W=1 is used for maximum availability and minimum consistency, where R + W = 2 does not exceed N and therefore offers no guarantee of quorum.
One of the most important reasons for R and W being generally designed to be less than N is latency. The latency of a get or put operation is measured by the slowest of the R or W replicas. Therefore, R < N and W < N provide lower latency with acceptable consistency.
System Architecture of DynamoDB
System Assumptions
DynamoDB is based on a number of assumptions that influenced its design. Regarding the query model, it is based on read and write access to data entities that are uniquely addressed by a key, with objects typically under 1 MB. Regarding ACID properties, DynamoDB is intended for applications that are able to support lower levels of consistency in order to provide high availability, with no isolation guarantees and support only for single-key updates.
From an efficiency perspective, the system is intended to operate on commodity hardware and meet 99.9th percentile latency requirements, with typically 99.9% of requests completing in 300ms. It is intended to operate only within Amazon's internal applications, where no authentication or authorization is required, and was originally designed to scale to hundreds of storage machines.
Techniques Used in DynamoDB's Design
DynamoDB combines a variety of techniques, each of which solves a particular problem in a distributed system. Partitioning is handled via consistent hashing, which provides incremental scalability by allowing nodes to be added or removed with little disruption. To provide high availability during write operations, DynamoDB uses vector clocks with reconciliation in reads, which has the benefit of decoupling version size from update rates. Handling temporary failures is accomplished via sloppy quorum and hinted handoff, which provide high availability and durability assurances even in the event that some replicas are unavailable.
As for handling permanent failures, DynamoDB uses anti-entropy with Merkle trees, which synchronizes divergent replicas in the background with no impact on foreground operations. Lastly, membership and failure detection are handled via a gossip-based membership protocol, which maintains symmetry among nodes and eliminates the need for a centralized registry to maintain membership and node availability information.
How DynamoDB Achieves Incremental Scalability
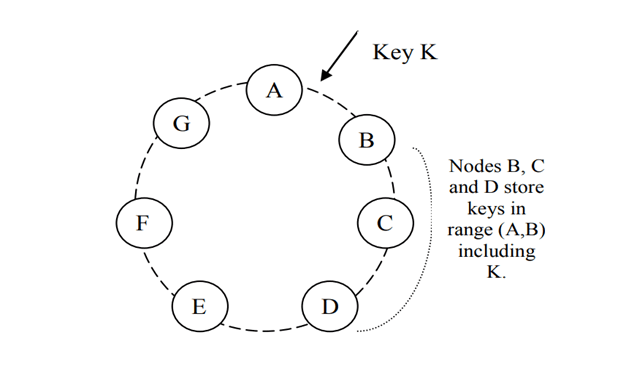
DynamoDB provides incremental scalability through sophisticated partitioning techniques based on consistent hashing with virtual nodes. The hash space is represented as a fixed circular hash ring, where multiple spots are allocated to each node represented by virtual nodes or "tokens." A data item is directed based on hashing the key and traversing the ring clockwise, with each node responsible for the region between itself and the previous node.
The introduction of virtual nodes provides several benefits. When nodes fail, the workload is equally distributed among the remaining nodes. When new nodes are introduced, they receive similar amounts of workload from each existing node. It also supports diverse infrastructure by allocating more virtual nodes to more powerful nodes. Adding and removing nodes is a very simple process. When a node X is introduced, it is allocated random spots on the ring, and other nodes that no longer need to service certain keys distribute those keys to node X. The reverse happens when a node is removed.
How DynamoDB Handles Conflict Resolution and Data Versioning
The conflict resolution mechanism in DynamoDB pushes this complexity to the application level rather than hiding it behind simplistic rules like "last write wins." The system implements a read-time resolution strategy where conflicts are resolved at the time of read and writes are never failed, adhering to the always writeable data store paradigm. Regarding who is responsible for conflict resolution, DynamoDB offloads this task to the application. As the application is cognizant of the data schema, it can use business logic-specific conflict resolution. A typical example is the shopping cart service, which merges conflicting versions to create a single unified cart.
To establish causality between versions, DynamoDB employs Vector Clocks. Each version maintains a list of (node, counter) pairs that allow the system to determine whether two versions represent parallel paths or have a causal ordering. If the counters on the first object are less than or equal to all counters in the second, the first object is an ancestor and can be discarded. Otherwise, the versions are conflicting and need to be resolved. Divergent versions are a rare occurrence in practice and are usually seen in concurrent writes rather than failures.
(Img - DynamoDB)
How DynamoDB Handles Failures?
Handling Temporary Failures: Hinted Handoff
DynamoDB does not enforce strict quorum membership and instead follows a "sloppy quorum," and all read and write requests are made to the first N healthy nodes in the preference list, which may not necessarily be the first N nodes encountered during a walk through the consistent hash ring. Each key is assigned to a coordinator node, which stores the key locally and replicates it to N-1 successor nodes in the clockwise direction.
For instance, if node A is momentarily down during a write request, a replica that would have otherwise resided in A is instead sent to node D, with a hint in the metadata that A was the target node. The nodes that accept hinted replicas maintain them in a local database that is periodically scanned. When it is noticed that A is back up, D tries to deliver the replica to A, and upon successful transfer, D removes the object from its local storage without reducing the overall number of replicas in the system. To guarantee durability, the preference list is designed such that storage nodes are distributed across multiple data centers, so that the system can survive the failure of entire data centers without a data outrage.
Handling Permanent Failures: Replica Synchronisation
Hinted handoff is most effective in scenarios with temporary node failures. In cases where hinted replicas are unavailable before they can be repatriated to the originating node, DynamoDB employs an anti-entropy function based on Merkle trees to maintain replica consistency. A Merkle tree is a hash tree where the leaves are hashes of individual key values, and the parent nodes are hashes of their children. If the root hashes of two trees are equal, the replicas are consistent.
Otherwise, the nodes compare child hashes recursively until they determine exactly which keys are inconsistent, requiring a minimal amount of data to be transferred during the synchronisation process. Each node in the system maintains a distinct Merkle tree for each key range it holds, enabling nodes to compare and synchronize simply by exchanging the roots of the Merkle trees associated with the key ranges they share.
How We Use DynamoDB at JM Financial?
In JM Financial, we utilise DynamoDB as a cache for key-value pairs to facilitate instant access to data. One of the most important design elements in our system is that we support most of our data access using Partition Key and Sort Key. This design element is consistent with the advantages provided by DynamoDB and provides us with significant performance advantages. We design our system to avoid table scans, which are expensive operations that consume a large amount of read capacity. Instead, we provide single-digit millisecond performance for direct key lookups, making our data access fast, predictable, and economical.
In addition to data access, we also utilise DynamoDB for authorization and role-based data filtering using a single-table design. Our design allows us to filter data based on the role of the user and the permissions provided to that role. When a user makes a request, their authorization object is retrieved from DynamoDB, which stores the role of the user and their respective permissions. The authorization object then determines what data the user can view and what operations they can perform on the data, providing seamless access control at the data retrieval level.
Disclaimer: Information is only for educational/Knowledge sharing purposes and not for soliciting any Investment or to influence investment/sale decisions of any person. The securities are quoted as an example and not as a recommendation. For registration details & disclaimer, please visit https://www.jmfinancialservices.in

Join thousands of learners
