Unlocking Hyper-Personalization: Inside the Nudge Engine Revolution
With the advent of AI and other similar advanced tools, offering a hyper-personalised experience to end customers has become an unsaid necessity. One way of offering such an experience is to deliver tailored, relevant nudges to users at the right time, via a channel of users’ choice.
This has turned out to build a differentiating moat for businesses, improve/retain customer loyalty and increase engagement. From food delivery apps like Swiggy and Zomato to dating platforms such as Tinder and Hinge, companies are embracing personalisation to create meaningful interactions. At BlinkX, a digital-first broking vertical of JM Financial, Hyper Personalised Nudge Engine (HPNE) was conceived to meet this need, bridging the gap between raw data and actionable engagement, addressing challenges of scalability, timing, and relevance.
Loosely Coupled Architecture: The Backbone of Scalability
The HPNE architecture is built on a loosely coupled, microservices-based design that ensures horizontal and vertical scalability that can deliver nudges at scale. The backend, implemented with core-java servlets, handles core business logic, while predictive machine learning models are exposed to the backend layer via FastAPI endpoints. The system is hosted on Google Cloud Platform (GCP) using a bouquet of serverless platforms like Cloud Run, App Engine that automatically scales-up to as high as 5,000 instances during peak time and then automatically scale down to 0 instances during off-time.
Data is managed by BigQuery (via a redis cache layer), again a fully managed, serverless data warehouse solution offered by Google that is optimised for running petabyte-scale SQL queries. This setup allows HPNE to process massive volumes of user interaction data with low latency. Communication between components is predominantly API-driven, triggered by event-based mechanisms and CRON jobs. For real-time applications, such as financial data streams, websockets are used to maintain a continuous flow of stock price data on a tick-by-tick basis.
The Machine Learning Core: Ensemble Models and Beyond
At the heart of HPNE lies a robust ensemble of machine learning models designed for relevance prediction and optimisation. RandomForest and XGBoost form the backbone of these predictive models, which take in non-correlated features from a large purview of data like user behaviour on our trading app, their trading-patterns, risk-aversion based on their stock selection, demographic, etc. The features are selected in a way to ensure that each nudge aligns with the recipient's interests.
We use a combination of online reinforcement along with a fallback of the offline reinforcement approach to classify good nudges from the bad nudges, for each nudge recipient. To evaluate whether the nudges delivered are to the mark, we measure metrics such as click-through rates (CTR) and user trade activities based on the nudges served. These metrics are used as benchmarks to evaluate and refine the models and build various kinds of use cases.
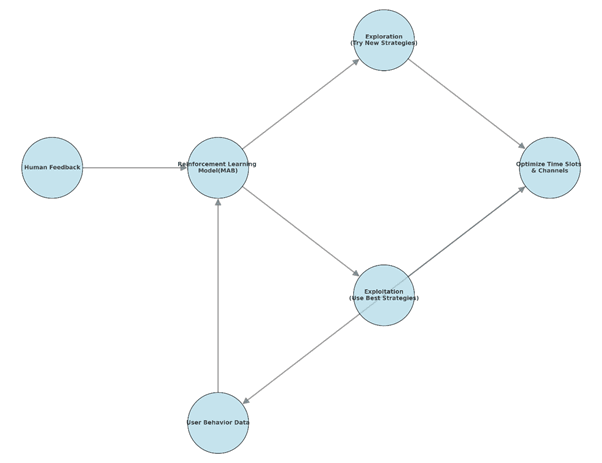
(Img - Fig: Reinforcement Learning Flow Diagram for MAB)
We also have a layer of Multi-Armed Bandit (MAB) framework, that goes out of the way to send nudges via exploration and exploitation, a key component in our RL layer. This model also uses human feedback, collected via ‘show-lesser of these’ button, which user can click on every nudge they receive. By balancing exploration (testing new strategies) and exploitation (leveraging known successful tactics), the MAB dynamically learns to identify the best category of nudge, the optimal time slots and the preferred channels for delivering nudges.
A Modular Pipeline for Personalisation
The HPNE (Hyper Personalised Nudge Engine) is structured into 5 distinct, modular stages namely
1] Signal Producer
2] Nudge Generator
3] Matchmaking Engine
4] Enrichment Layer
5] Delivery Engine
Each of these components work independently, in a containerized micro-service and interacts with other micro-services via a PubSub, which is an implementation of Kafka/Apache lucene, by GCP.
This modular nature facilitates easy updates and changes to each layer, and experimentation with different models, without affecting the rest of the HPNE components (they are all loosely coupled, remember?)
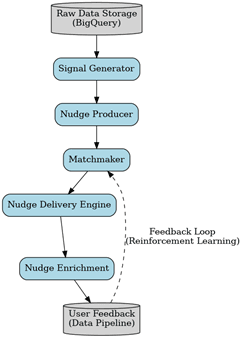
(Img - Fig: UML Diagram of HPNE)
Signal Generation: From Raw Data to Insights
Signal Generator, ingests millions of rows of raw data such are market-activity, user-events, trade placed, orders-rejected, tweets by major tweeter handles etc. This layer then parses all this data looking for signals that may be of relevance to the end users. This data is transformed into actionable signals and published on to relevant Topics, based on their categories like ‘Golden Crossover’, ‘Research-Call’, ‘Penny Stock Alert’ etc.
Nudge Production: Crafting Personalized Notifications
The Nudge Producer layer then subscribes to the topic of relevance and receive signals that were published by the Signal Layer. It maps these signals to users based on their historical behaviour (what kind of nudges user had clicked on previously), and current context (on what app-screen is the user currently on). Each notification includes essential details, such as the user name, product specifics, and actionable steps tailored to the user-nudge combination.
Matchmaking: Ensuring Relevance and Timing
The Matchmaking module is responsible for evaluating the relevance of a nudge and determining its optimal delivery time. Using a Proximal Policy Optimisation RL model, the matchmaking engine decides whether a nudge should be sent by passing a Yes or a No flag. The Matchmaker, over time, incorporates the feedback from user interactions, based on whether the user has clicked on the nudge, dismissed it (clicked on show lesser of these) and keeps improving its judgment.
Enrichment: Adding Contextual Flavor
This is the stage in the pipeline where the process of Enrichment of nudges takes place, where the templates are enriched with information, the grammar is enhanced and personalised according to the channel of delivery. For example, a WhatsApp notification would contain a personalised greeting and a call-to-action, while an email would contain insights and links based on the user's interests.
Delivery: Multichannel and Timely
Nudge Delivery Engine, the last layer in the HPNE architecture, handles the dispatch of notifications across 4 channels, namely app push notifications, email, SMS, and WhatsApp. We have a cloud task scheduler that schedules the delivery of nudges on an immediate basis or at a delayed time. The engine ensures that each nudge is delivered at the precise moment determined by the MAB-slot model. This engine has a multithreaded approach that ensures high throughput. The cloud task-scheduler is used to enforce retry policies, with exponential or customised delays that mitigate the impact of transient failures and reduce the load on failing service instances.
Built for Scale and Reliability
HPNE’s serverless architecture ensures seamless scalability, automatically adjusting resources to handle surges in user activity. The system is currently capable of identifying signals, mapping them to the right set of clients, enriching the content of the nudge and actually delivering the nudge via Push/SMS/WhatsApp/Email, all in real-time without any human intervention. As it stands, our system is capable of sending out 10Mn+ nudges within a few hours of market opening bell. By decoupling components and relying on API-driven interactions, the platform minimises dependencies and ensures high availability even under peak loads. Cache is also maintained in Redis to prevent re-computation of data for a user in a specified time period when we know the data won’t change.
Future Directions: AI-Driven Innovation
Looking ahead, we plan to incorporate cutting-edge tech, like finetuned LLMs in the enrichment layer, to enhance its personalised content generation capabilities. Improve the agent in the RL model to take better decisions and build a sophisticated delivery engine that aces the timing of nudge delivery. With the advancements in the AI domain, the infrastructure capabilities offered by Cloud Platforms will also grow in tandem. For instance, the number of transistors on a chip has become 2x from GeForce RTX 4080 with 45Bn transistors) to RTX 5090 (92Bn transistors)[3]. Such hardware development will help us use GenAI right out of memory, which help further help take hyper-personalisation to the next level. Plans are also underway to expand the range of supported channels, beyond the existing 5 channels, thereby making HPNE ubiquitous across platforms.
Disclaimer: Information is only for educational/Knowledge sharing purposes and not for soliciting any Investment or to influence investment/sale decisions of any person. The securities are quoted as an example and not as a recommendation. For registration details & disclaimer, please visit https://www.jmfinancialservices.in

Join thousands of learners
